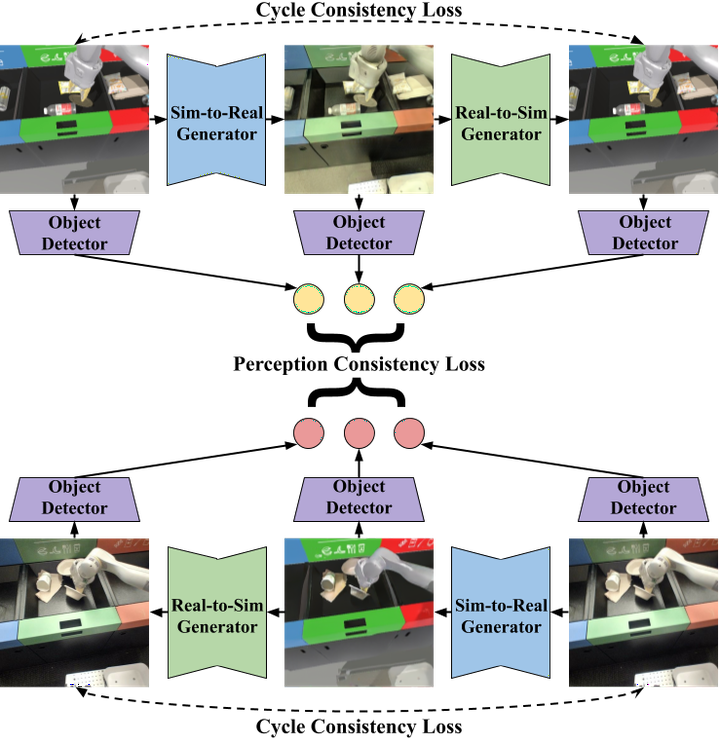
Abstract
The success of deep reinforcement learning (RL) and imitation learning (IL) in vision-based robotic manipulation typically hinges on the expense of large scale data collection. With simulation, data to train a policy can be collected efficiently at scale, but the visual gap between sim and real makes deployment in the real world difficult. We introduce RetinaGAN, a generative adversarial network (GAN) approach to adapt simulated images to realistic ones with object-detection consistency. RetinaGAN is trained in an unsupervised manner without task loss dependencies, and preserves general object structure and texture in adapted images. We evaluate our method on three real world tasks: grasping, pushing, and door opening. RetinaGAN improves upon the performance of prior sim-to-real methods for RL-based object instance grasping and continues to be effective even in the limited data regime. When applied to a pushing task in a similar visual domain, RetinaGAN demonstrates transfer with no additional real data requirements. We also show our method bridges the visual gap for a novel door opening task using imitation learning in a new visual domain. Visit the project website at https://retinagan.github.io.